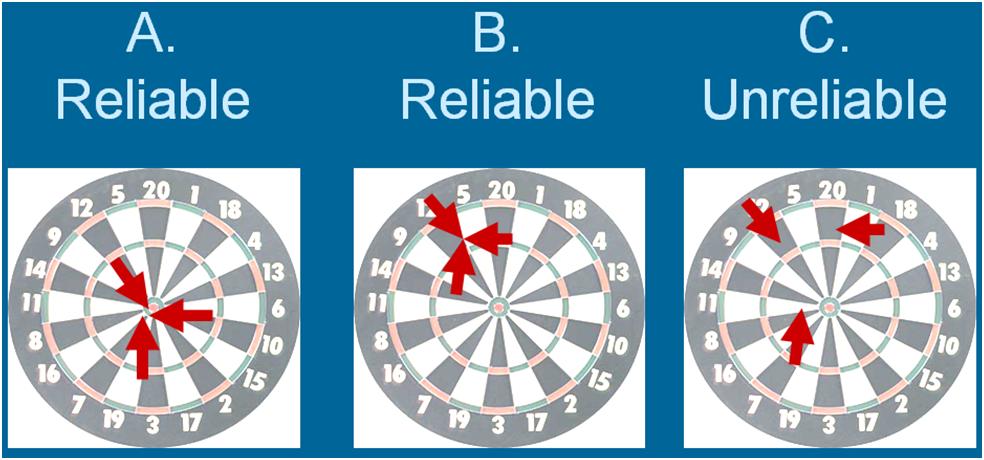
General explanations for calculating reliability indices are described below. If you need help calculating correlations, click Calculating Inferential Statistics.
Split-Half Reliability
Like its name, the general idea of split-half reliability is that a test is split into two halves. Then the two halves are correlated to determine how reliable the instrument is within itself. (Because of recent advances in statistics, this isn't entirely how split-half reliability is calculated anymore, but the philosophy is still the same.)
Because split-half reliability measures how internally consistent an instrument is, a reliability coefficient should be calculated separately for every variable that has two or more items to measure it. For example, if your study examines intrinsic motivation, extrinsic motivation, self esteem, and academic achievement, then you need four reliability coefficients - one for each variable. Therefore, the first step in calculating the split-half reliability is to divide the items into the variables that they measure.
A low split-half reliability (typically under 0.70) indicates that the instrument is poorly developed and needs to be revised. In the revision, focus on writing items that are directly related to the construct and operational definition of the variable.
To calculate split-half reliability, you must have every participant's response to every single item. More will be said about coding data in Analyzing Data. However, you need a table (preferably in Excel or SPSS) that looks something like this:
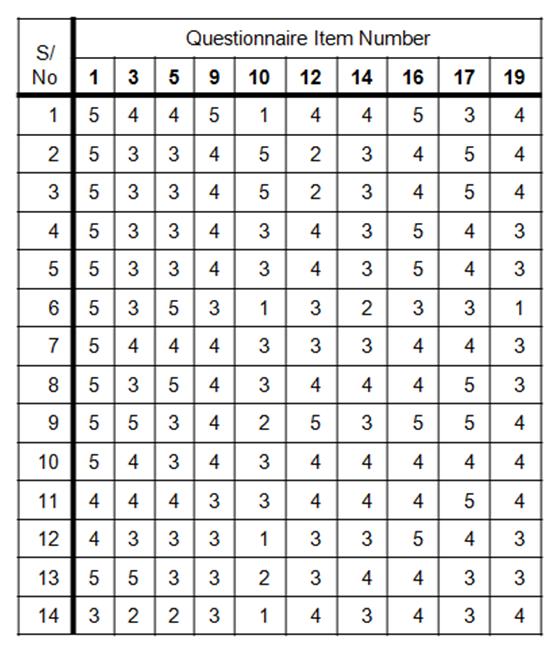
Each row is a separate participant who completed the questionnaire, listed by their Serial Number (S/No), and their responses to each of the items. Each column is a questionnaire item. Because the items measuring intrinsic motivation were spread throughout the questionnaire, items 3, 5, 9, 10, etc., were the items that measured this particular variable.
If you have access to SPSS or are mathematically inclined, it is best to calculate the split-half reliability with coefficient alpha. The formula for coefficient alpha is:
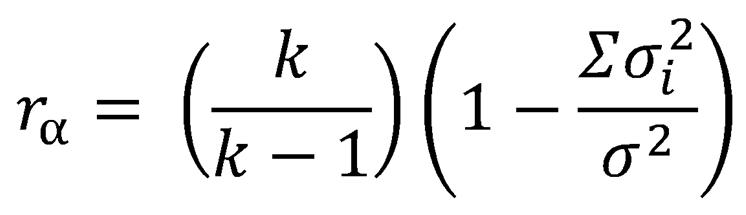
r stands for coefficient alpha; k is the number of items on the instrument that measure that variable, sigma sub-i is the variance of one item, and sum of sigma squared is the variance of the total score for the entire variable. That's complex, so only attempt to use coefficient alpha if you have been well taught how to do it.
Another option for calculating the split-half reliability is to do just that: split the items in half. In the example given above, items 1, 3, 5, 9, 10, 12, 14, 16, 17 and 19 all measure the variable of intrinsic motivation. If we split the items in half like this: 1, 3, 5, 9, 10 in one group AND 12, 14, 16, 17, 19 in the other, we might run into a problem: participants tend to get tired at the end of the questionnaire, so the second half of the items might not be as consistent as the first half, which will seriously lower the reliability coefficient. Instead, alternate the groups that the items are split into: 1, 5, 10, 14, 16 in Group A AND 3, 9, 12, 16, 19 in Group B. Then, for each participant, add up the scores on each item for Group A and the scores on each item for Group B, giving a total score for Group A and Group B. Then, those two total scores are correlated using the Spearman Brown Formula for correlations. Once that correlation is found, it is plugged into this simple split-half formula:
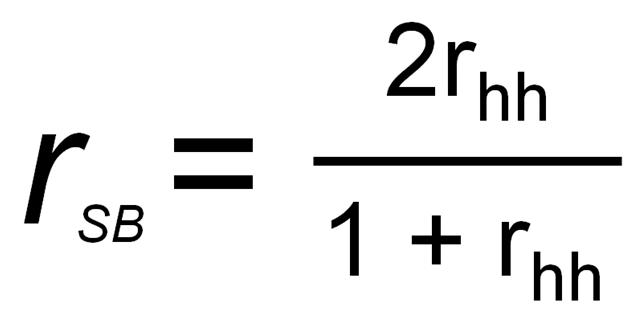
In this equation, r is the Split-Half Reliability Spearman Brown Formula, and r is the correlation between the two halves of the test.
For more details on calculating the split-half reliability, click here for a pdf file that goes into detailed demonstration of the process. (Note: Your computer must have Adobe Reader to view the document.)
Recall that the split-half reliability coefficient must be calculated for each variable that has more than one item separately. Therefore, you will have as many reliability coefficients as you have variables (that are measured by more than one item).
Parallel Forms Reliability
To calculate parallel forms reliability, first administer the two different tests to the same participants in a short period of time (perhaps with one week of each other). Then calculate the total score for each variable on the two separate tests. Your data should look something like this:
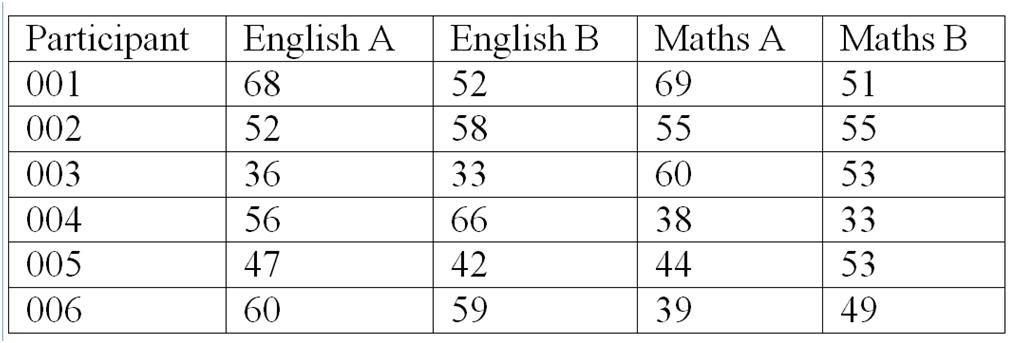
Total scores for English, Forms A and B are listed for each participant, as are total scores for Maths, Forms A and B. Now, calculate the Pearson's Product Moment Correlation between English A and English B. This is the parallel forms reliability coefficient for English. Then calculate the Pearson's Product Moment Correlation between Maths A and Maths B. This is the parallel forms reliability coefficient for Maths.
Test-Retest Reliability
For test-retest reliability, administer the same test to the same participants at two different times, perhaps two weeks apart. The data table will look similar to the Parallel Forms Reliability table above, except the columns will be entitled "English Time 1, English Time 2; Maths Time 1, Maths Time 2." Again, the Pearson's Product Moment Correlation should be calculated between English Time 1 and English Time 2. This is the test-retest reliability coefficient for English. Then calculate the Pearson's Product Moment Correlation between Maths Time 1 and Maths Time 2. This is the test-retest reliability coefficient for Maths.
Inter-Rater Reliability
Inter-rater reliability is used to calculate how consistent two "raters" (typically researchers or research assistants) are when they score the same test. The purpose of inter-rater reliability is not to correlate test scores, as are the previous three types of reliability. Instead, the purpose is to determine how consistent the raters are in their marks. Therefore, give the exact same tests to two raters, meaning that the same test will be marked by two different people. The data should look like this:
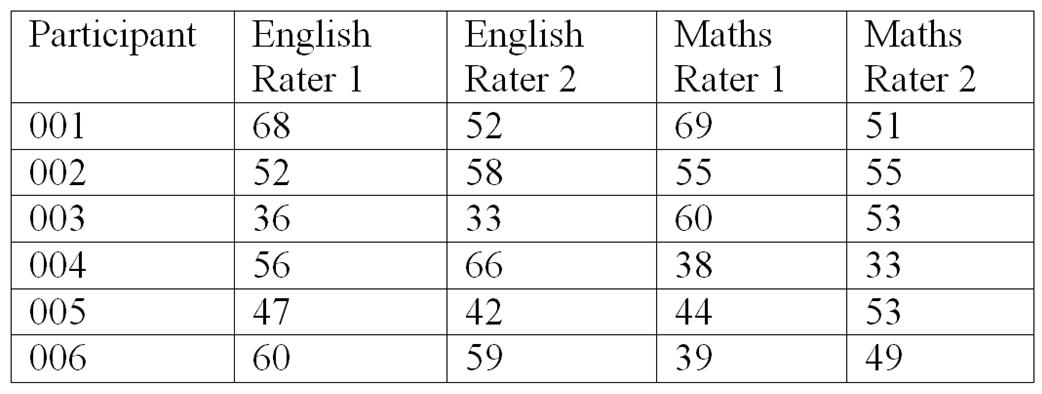
Rater 1 is the first teacher/researcher and Rater 2 is the second teacher/researcher. Calculate the Pearson's Product Moment Correlation between Rater 1 and Rater 2 on the English test, and again the Pearson's Product Moment Correlation between Rater 1 and Rater 2 on the maths test for the inter-rater reliability coefficients. A more advanced Kappa statistic should be used for inter-rater reliability for interview and observation data,
NEXT
Return to Educational Research Steps
Copyright 2012, Katrina A. Korb, All Rights Reserved