Construct validity is concerned about whether the instrument measures the appropriate psychological construct. (Recall that another word for construct is variable.) Formally, construct validity is defined as the appropriateness of inferences drawn from test scores regarding an individual's status on the psychological construct of interest. For example, a student gets a high score on a mathematics test. Does this mean that the student really knows a lot about mathematics? Another student gets a low score on the mathematics test. Does this mean that the student really does not know mathematics very well? If the student knows a lot about mathematics but happened to do poorly on the test, then it is likely because the test had low construct validity.
In a different example, a participant gets a high score on an assessment of intrinsic motivation. Does this participant really have high intrinsic motivation, meaning that they really enjoy the activity?
Consider the following item on a test designed to measure students' vocabulary skills. What is wrong with this item?
|
In all of the ________________ of packing into a new house, Sandra forgot about washing the baby.
a) Excitement
b) Excetmint
c) Excitemant
d) Excitmint
|
Is this item really measuring students' vocabulary skills, or does it measure something different? Since the item options give different spellings of the same word, the item is actually measuring spelling skills, not vocabulary skills. Therefore, this item would not be a construct valid item on a vocabulary test.
When considering the construct validity of an instrument, there are two things to think about. First, the quality of an instrument can suffer because of construct-irrelevant variance. This means that test scores are influenced by things that are unrelated (aka irrelevant) to the variable that it should be measuring. For example, a test of statistical knowledge that requires complex calculations is likely influenced by construct-irrelevant variance. In addition to measuring statistical knowledge, the test is also measuring calculation ability. A student might understand the statistics, but may have very poor calculation skills. Because the test requires complex calculations, that student will likely fail the test even though she has a good understanding of statistics. This reflects a test that does not have construct validity because there is construct irrelevant (unrelated) variance. Likewise, imagine an instrument to measure intrinsic motivation - enjoyment of the activity. Items that read: "I work hard in maths," "I like the maths teacher," and "I get good grades in maths" all introduce construct-irrelevant variance.
The second consideration in construct validity is construct under-representation. This means that a test does not measure important aspects of the construct. For example, a test of academic self efficacy should measure a participant's belief in their ability to do well in school. However, the items on the questionnaire might only measure self efficacy in math and science. This ignores the other important school subjects such as English and social studies. Therefore, this instrument does not represent the entire domain and therefore demonstrates construct under-representation. (This is also called content validity, more of which will be explained later.) If an instrument demonstrates construct under-representation, then it does not demonstrate construct validity.
There are three sources of construct validity evidence.
- Homogeneity: The instrument measures a single construct. This means that the instrument has high internal consistency as calculated by the split-half reliability. If an instrument is influenced by things that are unrelated to the variable, then it will have a low reliability and thus low construct reliability.
- Convergence: The instrument is related to other measures of the same construct and related constructs. A math test should have high correlations with other math tests. A measure of intrinsic motivation should have high correlations with other measures of intrinsic motivation. This is the same as criterion validity, which will be discussed in more detail soon.
- Theory: The test behaves according to theoretical propositions about the construct. For example, the theory of intrinsic motivation states that students who are intrinsically motivated are more involved in school, earn higher grades, and have more positive emotions than students who are not intrinsically motivated. Is this true for the intrinsic motivation instrument? on the assessment of intrinsic motivation? Likewise, the theory of intelligence states that intelligence increases with age. Is it true for an intelligence test that the intelligence test score for the same person increases as he gets older?
There is no one right way to gather construct validity evidence. Construct validity evidence largely comes from thoughtful consideration and a coherent argument in the Instruments section of Chapter 3 about how the instrument adequately relates to the variable that it is intended to measure. To evaluate the construct validity evidence of an instrument, you can report the split-half reliability coefficient to provide evidence of homogeneity, correlations from criterion validity to provide evidence of convergence and theory. You can also report content validity evidence to provide evidence of adequate construct representation.
Criterion Validity
Criterion validity reflects how well an instrument is related to other instruments that measure similar variables. Criterion validity is calculated by correlating an instrument with criterions. A criterion is any other accepted instrument of the variable itself, or instruments of other constructs that are similar in nature. For example, theory predicts that intrinsic motivation should be related to a person's behavior. Therefore, a person who earns a high score on an intrinsic motivation assessment to measure their enjoyment of an activity should engage in the activity when they are not required to.
There are three types of criterion validity. First, convergent validity demonstrates that an instrument has high correlations with measures of similar variables. An instrument that measures intrinsic motivation should be closely related to other instruments that measure enjoyment, perseverance, and time spent on the activity. Second, divergent validity means an instrument has low correlations with measures of different variables. Intrinsic motivation should have low correlations with measures of self efficacy, depression, and locus of causality. Finally, predictive validity means that an instrument should have high correlations with criterions in the future. For example, a measure of intelligence should predict future academic performance.
As an example of criterion validity, imagine science reasoning essay examination that was developed to admit students into a science course at the university. Criterion validity for this new science essay exam would consist of the following:
- Convergent Validity: The new science exam should have high correlations with other science exams, particularly well established science exams.
- Divergent Validity: The new science exam should have low correlations with measures of writing ability because the exam should only measure science reasoning, not writing ability.
- Predictive Validity: The new science exam should have high correlations with future grades in science courses because the purpose of the test is to determine who will do well in the science program at the university.
Criterion validity evidence for the new science test would look like this:
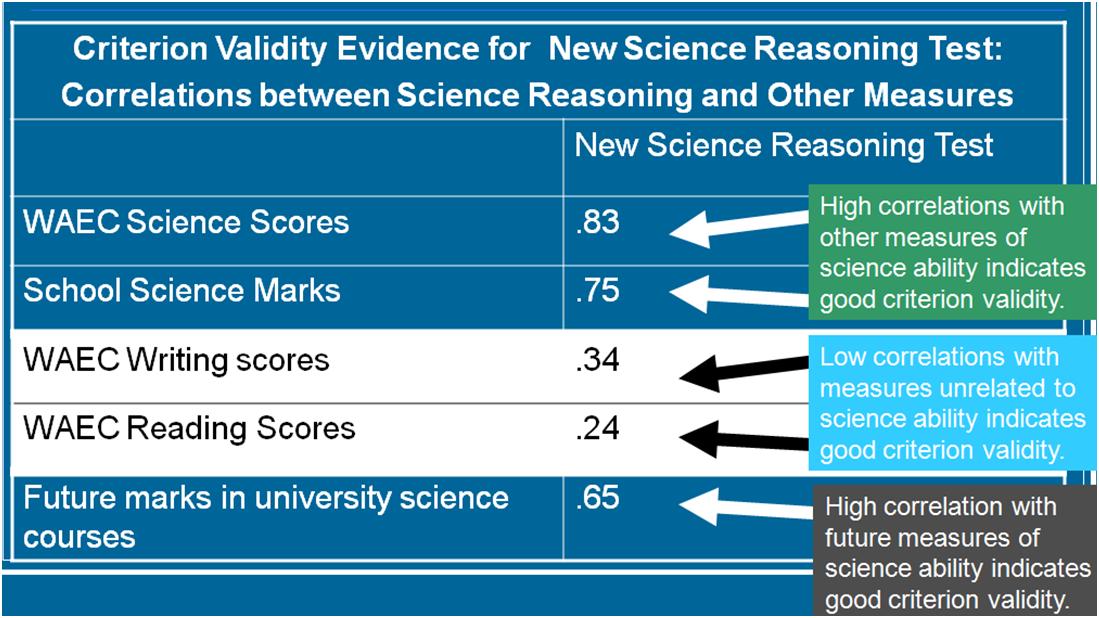
Therefore, to provide evidence of criterion validity, administer the instrument with other instruments measuring variables that are similar (and are predicted to have high correlations) and other instruments measuring variables that are different (and are predicted to have low correlations). The same participants should complete all instruments, and then calculate the correlations between assessments. For evidence of predictive validity, give a sample the instrument at Time 1. Then wait for time to pass (probably at least a year) and give the exact same sample an instrument of a variable that your instrument should predict. Then calculate the correlation between your instrument and the predictive criterion.
Content Validity
Content validity reflects whether the items on the instrument adequately covers the entire content that it should cover. Formally defined, content validity consists of sampling the entire domain of the construct that it was designed to measure. This is best understood in terms of a school examination. Classroom examinations should reflect the content that was taught in class. To be content valid, the amount of items on a test should be proportional to the amount of time the teacher spent covering that topic. For example, in a math class, the teacher spent this much time on each topic:
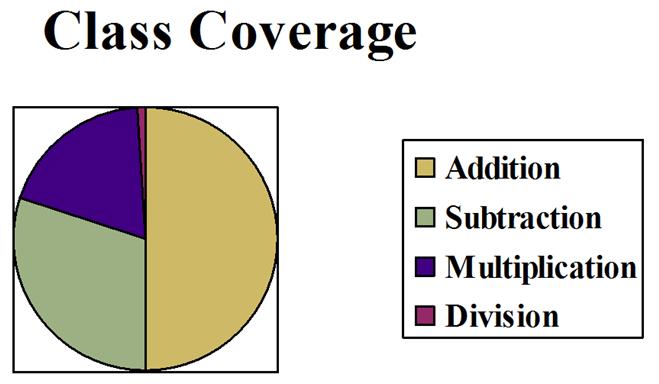
In other words, the teachers spent almost half of the class time on addition (the largest block of the circle). Then about 1/4 of the time was spent on subtraction, followed by a bit of time on multiplication. Practically no time was dedicated to division. The questions on the examination should reflect this division of time spent on each concept: about half of the items should be on addition, about 1/4 on subtraction, a few on multiplication, and practically none on division. However, the coverage of items on the exam looked like this:
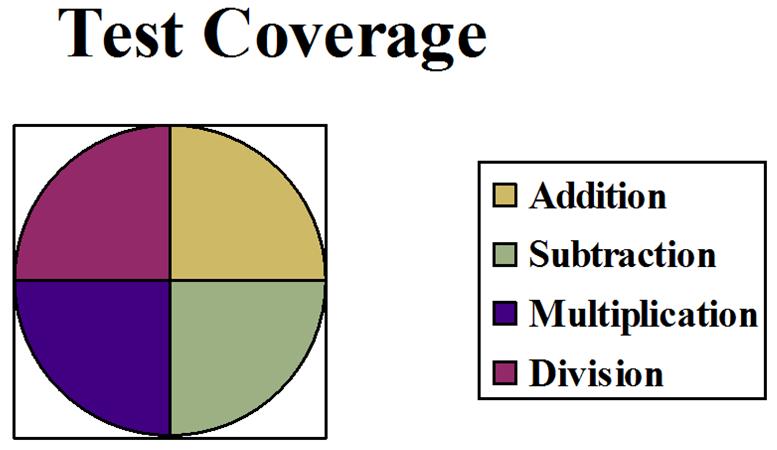
This exam does not demonstrate content validity. There were just as many items about division on the exam as there were items on addition! This is not fair to the students because the exam does not reflect the content validity of the course content. The chart for the number of items on the exam should be almost identical to the chart for the amount of time spent on the topic in class.
Typically, the content validity of an instrument should only be evaluated for academic achievement tests. To assess the content validity of an instrument, gather a panel of judges who are an expert in the variable of interest. Then give the judges a table of specifications of the amount of content covered in the class. How much time is spent in class for each topic? Then give the judges the instrument and an evaluation sheet. The judges should evaluate whether the proportion of content covered on the examination matches the proportion of content in the domain.
Face Validity
Face validity addresses whether the instrument appears to measure what it is supposed to measure. To assess face validity, ask test users and test takers to evaluate whether the test appears to measure the variable of interest.
However, face validity is rarely of interest to researchers. In fact, it is sometimes possible that an instrument should not demonstrate face validity. Imagine a test developed to measure honesty. Would it be wise for the participants to know that they were being assessed on their honesty? If the participants knew that, then the liars would lie on their responses to try to appear honest. In this case, face validity is actually quite damaging to the purpose of the instrument! The only reason why face validity may be of interest is to instill confidence in test takers that the test is worthwhile. For example, students need to believe that an examination is actually worth the time and effort necessary to complete it. If the students feel that an instrument is not face valid, they might not put forth time and effort, resulting in high error in their responses.
In conclusion, face validity is NOT a consideration for educational researchers. Face validity CANNOT be used as evidence to determine the actual validity of a test.
Conclusion
The best way to determine that the instruments used in a research study are both reliable and valid is to use an instrument that another researcher has developed and validated. This will assist you in three ways:
- You can confidently report that you have accurately measured the variables you are studying.
- By using an instrument that has been used before, your study is intimately tied to previous research that has been conducted in your field, an important consideration in determining the significance of your study.
- It saves you time and energy for not having to develop an instrument.
NEXT
Return to Educational Research Steps
Copyright 2012, Katrina A. Korb, All Rights Reserved